
고정 헤더 영역
상세 컨텐츠
본문
해당 포스팅은 고현웅 님께서 업로드 하신 Machine Translation Survey(Vol1): Background 영상을 참고해 만들었습니다. 관련 링크는 다음과 같습니다: https://www.youtube.com/watch?v=KQfvEg-fGMw
1. Sequence to Sequence
1) Encoder: 입력 받은 데이터를 이해해 이에 대한 일종의 보고서(Context vector)를 출력하는 모델
2) Decoder: 이 보고서를 입력 받아 어떤 문장을 생성하는 모델

→ 문제점: 입력이 엄청나게 길더라도 이 모든 내용을 fixed size 벡터로 축소해 보고서를 출력해야 함. 즉 해당 보고서로 내용을 완벽하게 표현할 수 없음! (빠지고 축소되고... 등등) 이는 문장 생성에서도 마찬가지!
2. Attention
Encoder가 이해한 내용을 한 번에 처리하는 것이 아니라 토큰 별로 정리해 출력하면 이를 토대로 Decoder가 내용을 정리한 후 유사도를 계산해 중요한 토큰만 추출하여 이를 바탕으로 문장을 생성하는 것

구조의 이해
문장 내 각 토큰(노란 박스) 별로 Key(encoder hidden state)를 출력 → 이를 토대로 Decoder의 hidden state인 query(빨간 동그라미)와 inner product를 통해 score를 계산 → softmax를 통해 확률 값으로 변경 시켜 앞서 추출된 key와 곱해 Value(alignment vector)를 출력 → 이 후 이들의 합을 새로운 시점의 입력으로 사용하는 과정에서 Decoder의 이전 스텝(분홍 동그라미)과 concat을 통해 다음 입력으로 사용
즉, 각 타임 스텝에서 Decoder의 Query와 Encoder의 Key 사이의 유사도를 반영시켜 사용하는 것!
3. Transformer
RNN의 Recurrent Unit을 제거하고 Multi Layer Perceptron과 Attention만 사용하는 새로운 형식의 뉴럴 네트워크
Transformer의 Encoder와 Decoder
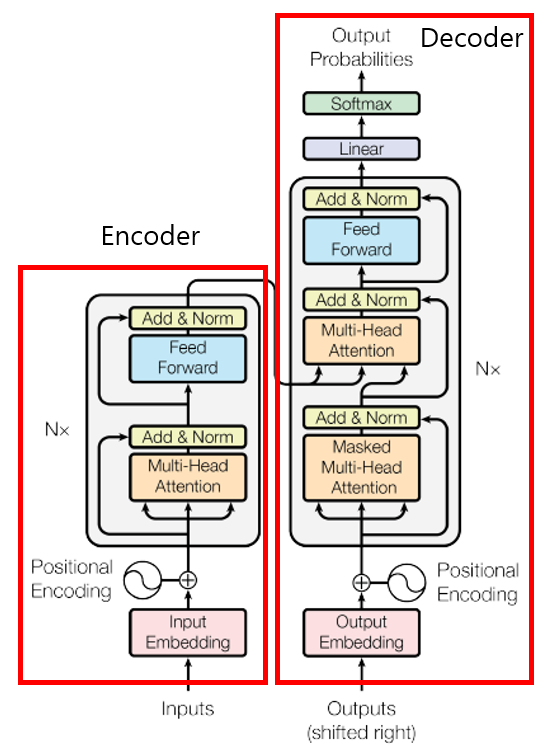
<Encoder>
Input Embedding + Positional Encoding
1) Input Embedding: 토큰화된 단어들을 임베딩 벡터로 만들어내는 과정
- Word2Vec보다는 Embedding Layer를 주로 사용
- Embedding Layer: 각 단어(토큰)에 대한 벡터를 가지고 있는 일종의 mapping 테이블

Embedding Layer 예시
2) Positional Encoding: 순서(위치)에 대한 mapping 테이블

각 토큰에 위치 정보가 반복돼서 더해지니 학습 과정에서 모델이 이를 눈치채 위치 정보가 반영되는 구조
Multi-head Self Attention
다른 문장이 아니라 같은 문장끼리 스스로 Attention 계산을 수행
- Transformer의 삼지창 (query, key, value): self-attention → 이 과정에서 벡터가 아닌 텐서를 사용하는데 이는 여러 토큰을 동시에 계산하기 때문
- 관련 이론은 다음 링크를 참조해주세용: https://kubig-2021-2.tistory.com/43?category=956772
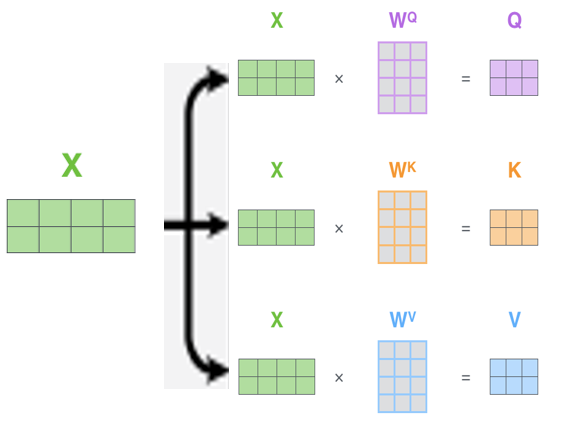
한 문장에 대해 3개의 tensor로 복사해 각각 query, key, value의 가중치를 곱해 서로 다른 tensor를 출력 - 계산 과정

1) MatMul: Query와 Key를 내적해 유사도 계산
2) Scale: 계산의 안정화를 위해 결과를 특정 상수로 나눠 스케일링
3) Softmax: 0과 1 사이의 값으로 변환
4) MatMul: 계산 결과를 Value와 곱해 줌
5) 최종 계산 결과 Z가 다음 레이어로 넘어감
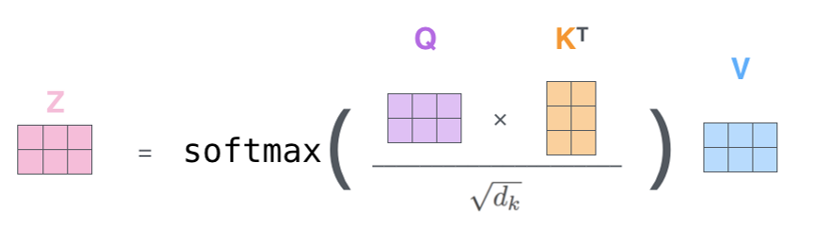
- Multi-head Self Attention
각 Query, Key, Value를 쪼개 head를 만들고 이에 대해 Self Attention을 거쳐 concat 해주는 메커니즘


위에서 만들어진 여러 개의 Z를 Concat 해 합쳐주고 size를 맞춰주기 위해 weight를 곱해주어 최종 output Z를 출력
→ Attention 맵을 여러개 만들어 다양한 경우의 수를 고려할 수 있음 (앙상블의 개념)
Addition & Layer Normalization
1) Addition: residual connection
→ Multi-head self attention의 출력 값을 기존 입력과 더해 반환
⇒ 다른 레이어가 망가지더라도 그래디언트가 잘 전달될 수 있기 때문에 모델이 좀 더 강건
2) Layer Normalization
- 분포를 안정적으로 바꿔주고 학습을 빠르게 만들어 줌
- 자연어의 경우 입력 시퀀스의 길이가 매번 다르기 때문에 Batch Normalization(배치 사이즈 dimension에 normalization) 보다는 Layer Normalization(feature dimension에 normalization)이 적합
Positionwise Feed Forward Network
Feature를 4배로 키웠다가 다시 줄이고 반환
⇒ 위의 과정을 총 6개의 레이어로 중첩해 반복: 이 출력값이 Decoder의 key, Value로 넘어감
<Decoder>
Output Embedding + Positional Encoding
Decoder는 정답으로 사용할 문장을 한 칸씩 밀어서 입력

Masked Multi-head Attention
역삼각형 마스킹이 추가된 Multi-head Attention
- Teacher Forcing을 통해 라벨을 입력할 때, 다음 단어가 무엇인지 알고 Attention을 계산하면 치팅하게 됨
- 위의 그림에서 A, B, C, D는 순차적으로 생성되지만 학습할 때는 동시에 넣어주는데, 모델은 A 다음에 B가 나온다는 사실을 몰라야 하지만 동시에 넣어주면서 이를 모델이 알아버리는 것이 치팅 현상. 따라서 생성하는 뒷부분의 Attention을 막아주어야 학습이 가능
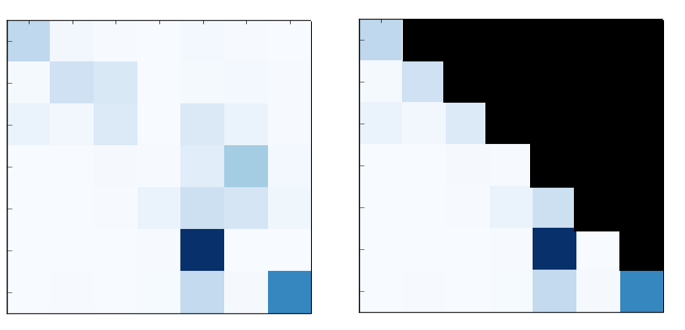
Encoder의 Attention(왼쪽)과 Decoder의 Masked Attention(오른쪽)
Encoder-Decoder Attention(=Cross Attention)
Encoder와 Decoder가 연결되는 부분
- RNN attention과 마찬가지로 Key, Value는 Encoder로부터 받고 Query는 Decoder가 현재 생성하고자 하는 Representation
- Encoder의 6개 layer를 거친 최종 representation이 Decoder의 각 6개 layer에 key와 value로 제공

Decoder의 구조 중 Cross Attention
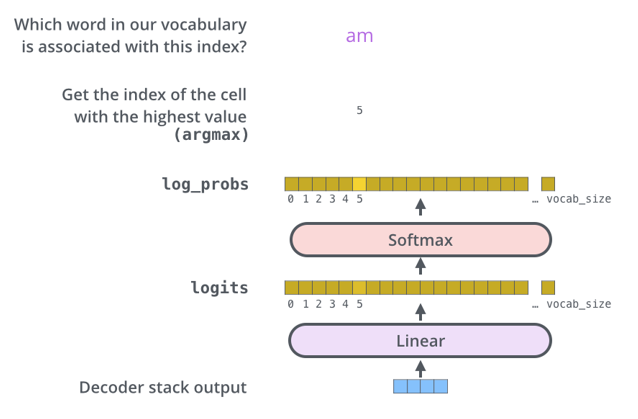
Final Linear & Softmax
출력된 벡터가 Linear를 거쳐 사전의 크기만큼 커지고 logit 값은 값이 너무 크거나 작으니 Softmax를 거쳐 확률 값을 출력
4. GPT
Semi(Self) Supervised Learning
1) 수많은 Unsupervised 데이터로 모델을 학습시키고
2) 적은 Supervised 데이터로 모델을 Fine Tuning 하는 아이디어 WOW!: semi
3) 단, Unsupervised 데이터에서도 사람 없이도 자동으로 라벨이 가능: self
- Transformer의 Decoder만 사용한 모델 (생성 task에 특화) → Encoder가 없으므로 Cross Attention이 없음

GPT의 구조 - 이 계층에 Causal Language Model 수행: 단어들을 보고 다음 단어를 맞추는 task → Pretrain 단계에서 Unsupervised 데이터에 대해 사람의 손을 거치지 않고 기계적으로 생성 가능 (Self-Supervised)
- 구조를 약간 수정해 매우 적은 수의 Supervised 데이터셋으로 Fine Tuning해 여러 task를 풀어보게 함 → 좋은 성능을 보임
5. BERT
BERT는 Transformer의 Encoder로 만든 모델 (이해 task에 특화)
→ Pretrain 단계에서 2개의 문장을 받아 다음과 같은 포맷으로 만들어 줌

- Token Embedding
1) CLS 토큰: 문장 분류나 문장 임베딩에 사용할 수 있는 기능성 Class 토큰
2) SEP 토큰: N개의 문장을 구분 지어 주는 Separator 토큰

- Segment Embedding: 각 문장에 다른 임베딩을 더해주어 문장을 구분하는 계층

Segment Embedding - Positional Embedding: Postional Encoding과 같은 개념 (사전에 정의된 table이 아니라 random으로 matrice를 초기화한 후 역전파를 사용해 학습하게 함 → Position 간의 연관 관계도 파악 가능)
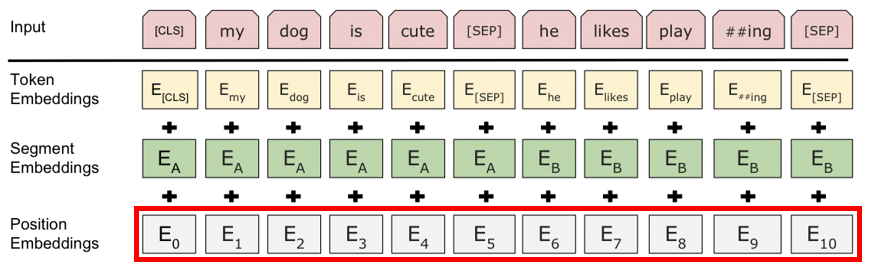
Positional Embedding
⇒ 이렇게 만들어진 입력 구조로 BERT는 두 가지 Pretrain task를 풀게 됨
1) Masked Language Modeling: MLM
→ 문장의 일부(15%) 토큰을 랜덤으로 변경 (80%: MASK, 10%: Other, 10%: 그대로)
2) Next Sentence Prediction: NSP
→ 두 문장을 SEP 토큰으로 구분해 입력: 원래 이어지던 문장인지 아닌지 이진 분류를 맞추는 task
위의 task를 마찬가지로 모델의 구조를 약간 바꾸고 적은 양의 Supervised 데이터를 사용해 학습
⇒ 엄청나게 많은 task에서 최고의 성능을 보임
6. AR & AE & DAE
1) AR: Auto Regressive
이전 타임스텝의 출력이 다시 입력이 되는 것
ex) RNN, GPT와 같은 Causal Language Model을 푸는 모델들 → 언어 생성에 적합
2) AE: Auto Encoding
입력을 그대로 복구하는 인코더-디코더 모델링
ex) VAE
3) DAE: Denosing Auto Encoding
입력에 고의로 noise를 주고 원래대로 복구하는 작업
'심화 스터디 > NLP 스터디2' 카테고리의 다른 글
| 3. BART: Denoising SequencetoSequence Pretraining for Natural Language Generation Translation and Comprehension 논문 리뷰 (0) | 2021.09.25 |
|---|---|
| 2. Fine-tune BERT for Extractive Summarization 논문 리뷰 (0) | 2021.09.19 |
| 0. [Paper Review] Transformer to T5 (XLNet, RoBERTa, MASS, BART, MT-DNN,T5) (0) | 2021.09.19 |
| 1. Attention is all you need 논문 리뷰 (0) | 2021.09.18 |
| NLP 스터디2 소개 (0) | 2021.08.27 |



댓글 영역