
고정 헤더 영역
상세 컨텐츠
본문
Abstract
- 본 논문에서는 BERT를 extractive, abstractive model 모두에게 사용할 framework를 제안한다.
- Extractive
- encoder의 맨 위에 inter-sentence Transformer layer를 쌓아서 생성
- Abstractive
- 새로운 Fine-tuning schedule
- Two-staged fine-tuning
Introduction
모델 등장 배경
- 대부분의 pretrained language model은 분류 task를 위한 문장 & 문단수준의 자연어 이해를 위한 인코더로 채택 됐다.
- → 텍스트 요약을 위해서는 previous task와 다르게 요약에는 개별 단어와 문장의 의미를 이해하는 것을 넘는 광범위한 이해가 필요
- 세 가지의 기여
- 요약 task를 위한 문서 인코딩의 중요성 강조
- Extractvie & Abstractive summarization 모두에서 사전 훈련된 언어 모델을 효과적으로 사용하는 방법 제시
- 추후 비슷한 연구들의 baseline이 될 수 있음.
Background
Pretrained Language Model
- Pretrained language model
- 다양한 자연어처리 task에서 좋은 성과를 얻기위한 핵심기술로 부상함.
- 대규모 말뭉치로부터 contextual representation을 학습함으로써 단어 임베딩에 대해 extend 된 모델들.
- BERT : masked language modeling과 3,300M 단어 말뭉치에 대해 "다음 문장 예측"을 중심으로 훈련된 language representation model이다.
Extractive Summarization
: 가장 중요한 문장을 식별하여 요약문 생성
Proposal
- Neural models : extractive summarization을 일종의 요약문에 해당 문장 포함할지 말지 문장 분류문제
Abstractive Summarization
- Neural Approaches to abstractive summarization : task를 sequence to sequence로
- encoder :
- mapping x=[x1,x2,...,xn] (a sequence of tokens) → z=[z1, ... , zn](continuous representations)
- decoder :
- 토큰별로 target summary 생성 y=[y1,..., ym]
- In auto-regressive manner, 모델링 조건부 확률 : p(y1,...,ym |x1,...,xn)
- encoder :
Fine-tuning BERT for Summarization
Summarization Encoder
- 기존의 BERT의 문제점
- BERT는 MLM로 훈련되므로 문장이 아닌 단어에 대한 표현을 출력
- NSP 때문에 모델 구조가 두 개의 문장만 입력받을 수 있도록 설계됨
- BERT 기존의 positional embedding은 최대 길이가 512
BERTSum

- increasing CLS 토큰 → 여러 문장의 특징 추출
- interval segment embedding → 여러 문장 구분할 수 있도록 교차로 Ea, Eb 적용
- 무작위로 초기화하고, 인코더에서 다른 매개변수로 finetuned 되는 더 많은 Positional Embedding을 추가하여 이 limitation을 극복
Document Representation
: 하위 Transformer layer가 인접한 문장을 표현하고, 상위 Transformer layer는 여러 문장의 결합 형태를 표현
Extractive Summarization (BERTSUM)
- d=[sent1,sent2,...,sentm]
- document에 i번째 sentence를 요약문에 포함시킬지 말지 {0,1}을 label
- i번째 문장을 나타내는 [CLS]를 입력하면 t(i)라는 문장벡터 출력
- 몇층을 쌓을지는 초모수로 결정!!
- l = 2일때 가장 성능이 좋았음. (BERTSUMEXT)
- → t(i)를 inter-sentence Transformer Layers에 입력하여 문장단위 특성을 포착
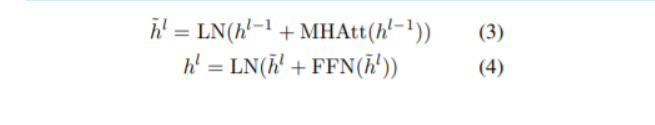
- h^0=PosEmb(T) ; T 는 BERTSUM에 의한 sentence vector를 의미한다.
- PosEmb : vector T에 positional embedding을 더해주는 함수

Abstractive Summarization
- 기존의 encoder-decoder framework 사용 시 문제점
- Encoder : 사전학습 되어 있음
- Decoder : 랜덤 초기화

- → 이를 해결하기위해 새로운 fine-tuning 스케쥴 도입. 서로 다른 두 개의 Adam optimizer를 이용 : 다른 warmup-steps and learning rate !!
- pretrained 된 Encoder를 더 작은 학습률로 천천히 미세조정
- two-stage fine-tuning
- 1차 fine tuning : Fine-tune 인코더 on extractive summarization task → abstractive summarization의 성능을 높임
- architecture의 변화없이 두 task(추상, 추출) 간의 공유되는 정보를 활용할 수 있음.
Experiment Setup
Summarization Datasets
- Datasets
- the CNN/DailyMail news highlights dataset : Extractive & Abstractive
- the New York Times Annotated Corpus (NYT): Extractive & Abstractive
- XSum: Abstractive
- the CNN/DailyMail
- 뉴스 기사 & 관련 하이라이트 : 기사에 관한 간략한 개요를 제공함
- 입력 document 512 tokens로 제한
- the New York Times Annotated Corpus (NYT)
- article + 그에 관한 abstractive summary
- 입력 document 800 tokens로 제한
- XSum
- 뉴스기사 + "무엇에 관한 기사입니까?"의 질문에 대한 한 문장의 요약 ( 226,711개 )
- 입력 document로 512 tokens로 제한
Implementation Detail
- Pytorch, OpenNMT 사용 → source & target 토크나이징
Extractive Summarization
- 50,000 steps with gradient accumulation every two steps.
- 1,000 step 마다 → Model checkpoint 저장
- 상위 3개 체크포인트 선택 → 평균내서 결과 저장
- Abstractive model 훈련을 위해 greedy algorithm으로 oracle summary 생성
- ROUGE-2 score를 gold summary(정답) 에 대해서 최대화하는 여러 문장을 뽑는 알고리즘
- 새로운 document에 대한 요약을 예측할 떄, 모델을 사용하여 각 문장의 점수를 얻는다. 그 후 가장 높은 상위 3개의 문장을 요약으로 선택한다.
- Trigram Blocking을 이용해서 중복된 문장의 선택을 막는다.
- summary S에 대해서 후보 문장 c가 있을때, if there exists a trigram overlapping between c and S → 후보 문장을 요약문에서 제외
Abstractive Summarization
- 모든 abstractive model : 모든 선형 레이어 앞에 드롭아웃(0.1)을 적용
- Label Smoothing with smoothing factor 0.1
- Transformer Decoder :
- 768 hidden units
- 2048개의 hidden size for feed-forward layers
- 200,000 steps with gradient accumulation every five steps.
- 2,500 step 마다 → Model checkpoint 저장
- 상위 3개 체크포인트 선택 → 평균내서 결과 저장
- 디코딩하는 동안 Beam Search (size 5) 사용 : 패널티 (0.6~1) on the validation set
- End-of-sequence token이 나올떄까지 디코딩
- Trigram Blocking → 다양한 요약 생성 ( 중복을 줄이기위해 )
- Decoder가 Copy & Coverage Mechanism 사용 X → minimum-requirement model을 만들기 위해서
Results
Automatic Evaluation
- ROUGE 평가지표 사용
- Informationess and longest common subsequence 평가.
- ROUGE-1 : unigram
- ROUGE-2 : bigram overlap
- ROUGE-L : fluent(유창함) 평가
- Informationess and longest common subsequence 평가.

- ORACLE : upperbound
- LEAD3 : base-line (앞의 3문장 이용 )
- BERT-based model은 다른 abstractive model, extractive model보다 뛰어남
- → interval segment embedding은 아주 조금 성능 향상
- → BERTSUMEXT(large)가 가장 좋은 성능.
NYT Dataset

→ 거의 다 위와 같은 내용
→ ORACLE의 성능에 매우 가까움
XSum

→ BERT-based model의 매우 우수한 성능
Human Evaluation
- 요약 모델이 문서의 핵심 정보를 유지하는 정도를 정량화하기 위해 Q&A 패러다임에 따른 실험을 진행.
- 정답 (label)을 기준으로 질문들을 만들어서 model이 생성한 요약만을 보고 대답하도록함.
→ 더 많은 질문에 답할 수록, 더 좋은 summarizing 능력을 가진다고 본다.

→ 최신 system들과 GOLD (upperbound), LEAD( baseline ), BERTSUM 모델 비교
Conclusion
- pretrained BERT는 텍스트 요약에 유용하게 활용될 수 있음을 보여줌.
- Abstractive & Extractive summarization을 위한 프레임워크를 제안함
- 새로운 문서 수준의 인코더를 도입함.
- 세가지 데이터셋에 대한 실험결과는 BERTSUM 모델이 자동 및 인간 기반 평가 지표에도 최첨단 결과를 달성한다는 것을 보여준다.



댓글 영역