
고정 헤더 영역
상세 컨텐츠
본문
딥러닝 기반 모델 발전
최신 고성능 모델들은 Transformer 아키텍처를 기반으로 하고 있다.
- GPT : Transformer의 디코더(Decoder) 활용
- BERT : Transformer의 인코더(Encoder) 활용
0. Abstract
이전까지는 인코더와 디코더를 포함해 시퀀스를 변형시키는 RNN/CNN 기반 모델을 전적으로 사용
인코더/디코더 구조 + Attention 메카니즘 : 성능 향상
본 논문에서는 Attention 메카니즘에 전적으로 기반을 둔 Transformer 아키텍처 제안
- 각 sequence를 반복해서 처리할 필요가 없으므로 행렬곱을 이용해 병렬 처리 가능 - 시간 단축
- WMT 2014) 영→독,영→불 변환하는 Task에서 성능 개선
- seqeucne를 처리하는 여러 task에 일반화 적용 가능
1. Introduction
RNN, LSTM, GRU 등의 여러 딥러닝 모델 존재 : sequence 모델링에 효과적으로 이용
그러나, 시퀀스에 포함된 각 토큰들에 대한 순서 정보를 먼저 정렬시킨 후 반복적으로 입력에 넣어 히든스테이트를
갱신시키는 방법으로 동작
- 시퀀스의 길이, 즉 토큰의 개수만큼 neural network에 입력을 넣어야 하므로 병렬적 처리가 어려움
- layer의 output에 문장의 길이만큼 입력을 수행해야 하므로 메모리, 속도 측면에서 비효율성 야기
Seq2seq 모델의 한계점
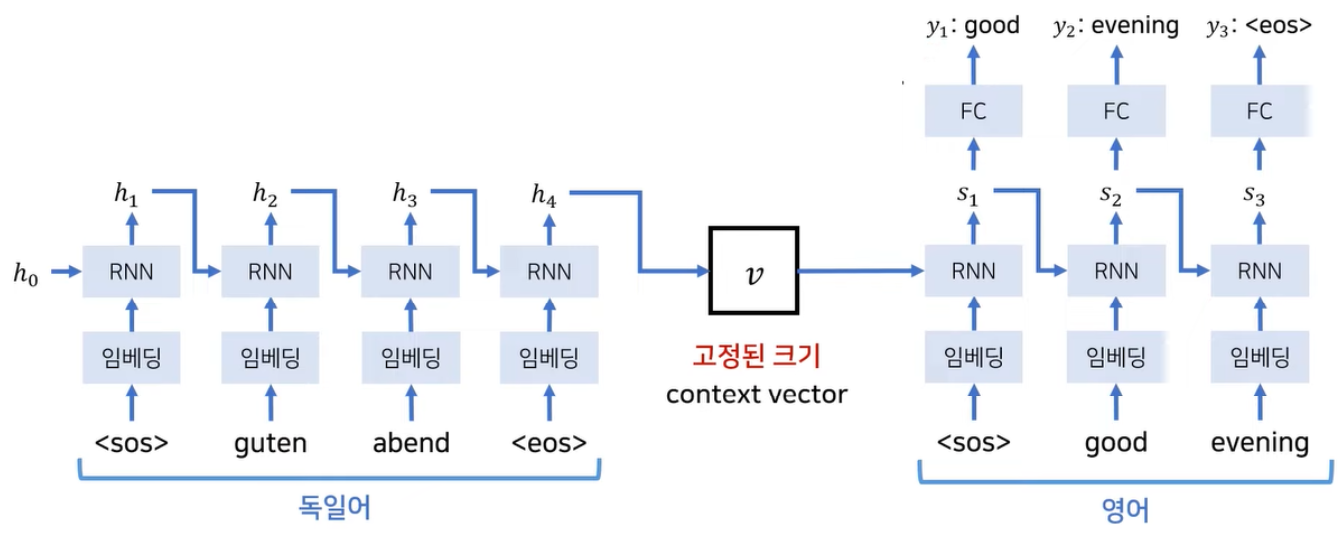
문맥 벡터가 인코더의 모든 시퀀스 정보를 포함하고 있으므로 decoding 시 개별 토큰과의 관계파악이 어렵다.
Sequence가 길어지는 경우 RNN의 고질적인 문제 중 하나인 기울기 소실(Gradient vanishing) 위험이 있다.
⇒ 하나의 문맥 벡터가 소스 문장의 모든 정보를 담기 어려움! 성능이 저하된다.
Attention 메카니즘
현재 출력 대상에 대해 모든 Encoder의 hidden state를 고려할 수 있다.

- 매번 출력 단어를 만들어낼 때마다 소스 문장의 출력 정보 중 어떤 정보가 가장 중요한지에 대해 가중치를 부여
- 가중치가 적용돼 곱해진 히든 스테이트 값 이용
- 출력값을 보다 효율적으로 생성
- 다만 기본적으로 RNN과 함께 사용되는 경우가 많음!
Transformer
- "Recurrence" 특성 자체를 완전히 제거, Attention 메커니즘만 사용해 모델의 결과 출력
- 한 번의 행렬곱으로 위치 정보가 포함된 전체 시퀀스를 한 번에 처리 가능!
- 순차적으로 입력을 넣지 않아도 되므로 병렬 처리 가능 ⇒ 성능 크게 향상!
- 8개의 P100 GPU를 사용했을 때 12시간만에 좋은 성능을 얻을 수 있음
2. Background
Self-attention
- 특정 문장이 있을 때 자기 자신의 문장 스스로에게 attention을 수행해 학습하는 것
- 하나의 시퀀스가 있을 때 그 시퀀스에 포함된 서로 다른 위치 정보가 서로가 서로에게 가중치를 부여하게 만들어 하나의 시퀀스에 대한 representation을 효과적으로 학습, 표현
예) I am a teacher → 4개의 단어는 서로에게 어텐션 수행, 가중치 부여
3. Model-Architecture
대부분의 성능이 좋은 시퀀스 모델 : Encoder-Decoder 구조를 지님
Encoder : n개의 입력 시퀀스를 임베딩 벡터 z로 변환
Decoder : 벡터 z에 대해 m개의 토큰으로 구성된 출력 문장을 만듦
RNN 구조 모델 : 시퀀스의 길이만큼 네트워크에 입력되는 방식
- 이전 단계에서 생성된 symbol을 이용해 다음 번에 나올 출력값을 만드는 방식으로 동작
Transformer 모델 : Encoder-Decoder 구조로 구성
- 기본적인 아키텍쳐는 활용
- 차이 : 모델을 recurrent하게 이용하지 않고 attention 메커니즘만 활용해 sequence에 대한 정보를 한 번에 입력

1) Encoder
Positional Encoding : RNN을 사용하지 않는 대신 문장 내 포함된 단어들의 위치정보를 인코딩해 입력하기 위해 사용
- Input Embedding과 동일한 dimension으로 합치기를 수행
- Query, Key, Value 값으로 각각 복제돼 입력
- Multi-Head Attention : Self-attention으로 동작
- Residual Connection 수행, 정규화 수행
- Feed Forward 수행 후 Residual Correction, 정규화 수행
- Attention은 입력과 출력 차원(논문 : Embedding 벡터 차원 = 512)이 같음
- 위 과정을 N번(논문에서는 6번) 진행해 N개의 인코딩 레이어를 쌓음
- 마지막에 나온 출력값을 매 Encoder-Decoder 어텐션에서 사용
2) Decoder
① 출력된 단어만 Attention 수행하도록 학습 수행 시 mask를 씌워 뒤쪽 단어는 미리 알지 못하도록 만듦
- Masked Multi-Head Attention : Query, Key, Value 값이 같음
: self-attention 수행
② Multi-Head Attention : Query 값이 Decoder에 있으므로 각각의 출력 단어를 만들기 위해 Encoder 파트에서 어떤 정보를 참고하면 좋을지 attention 수행
- Key, Value 값은 Encoder에서 받음
③ Feed Forward 수행
④ Linear layer 수행, Softmax 수행해 실제 각각의 출력 문장에 포함된 단어들이 어떤 단어에 해당하는지 구할 수 있음
3) Multi-Head Attention
Scaled Dot-Product Attention


- 각 Query가 Key에 대해 질문을 하는 내용을 행렬 곱
- Softmax 들어가기 전 값을 scale하는 Scale Layer(루트 나눗셈형태)
- Softmax 함수를 취해 각 key에 대해 중요한지 확률값 출력
- 각 확률값을 각각 Value 값과 곱해 attention 값을 출력
※ Dot-Product : 속도 빠름, 공간 효율적 방법
※ Scaling하는 이유 : Softmax는 중간 부분이 gradient가 상대적으로 크고 사이드로 갈수록 gradient가 작아지는 특징, 값이 너무 커지면 gradient가 너무 작아져 학습이 잘 안 될 수 있다. 특정 scale factor만큼 곱해 값을 작게 만들어 학습이 잘 이뤄질수 있도록 함
Multi-Head Attention


- 입력값이 들어왔을 때 V,K,Q에 대해 각각 복제됨
- Linear Layer는 임베딩 차원을 Key, Query, Value의 차원으로 변환
- Scaled Dot-Product Attention 수행
- 출력된 attention 값은 각 head 개수만큼 다르게 이뤄짐
모델의 차원과 별개로 key, value, query 각각의 차원을 결정할 수 있음
나중에 다시 이어붙이므로 결과적으로 입력과 출력의 dimension은 같아짐! - 다시 결과를 합쳐 Linear layer를 거쳐 output 생성
Transformer에서 Multi-head Attention을 활용하는 곳
① "Encoder-Decoder attention" layer : Query는 이전의 Decoder layer에서, Key와 Value는 Encoder의 출력에서 가져옴
- 출력 단어를 만들기 위해 소스 문장에 포함된 단어 중 어떤 정보에 보다 초점을 맞출지 계산하는 과정!
② Encoder 파트 - "Self-attention" : Query와 Key, Value가 모두 같은 형태.
③ Decoder 파트 - "Self-attention" : "mask"를 씌워 softmax에 들어가는 값이 -∞이 돼 0%가 부여될 수 있도록 함!
- 각 단어가 앞부분의 단어만 참고할 수 있도록 하기 위함
4) Feed-Forward Networks

max 함수 : ReLU 활성화를 위해 사용
인코더와 디코더의 각 layer는 모두 FFN을 포함
각 위치별로 선형 변환(linear transformation)하는 것은 동일하지만, layer별로 적용 모수는 모두 다르다.
5) Embeddings and Softmax
Seq2seq 모델에서 사용되는 방법과 동일
Input dimension : 특정 문장에 포함된 단어의 개수에 비례
→ Embedding layer를 거쳐 임베딩 차원으로 mapping
6) Positional Encoding

Transformer 모델은 Attention mechanism만 전적으로 활용
- recurrence와 convolution을 모두 사용하지 않는다!
- 위치에 대한 정보값을 함께 주기 위해 인코딩 정보를 더해 넣어줌
- 주기함수(sin,cos 함수)를 이용
- 함수 대신 임베딩 레이어를 별도로 학습하도록 해서 네트워크를 구성할 수도 있음!
- 실제로 성능상 큰 차이 없음! 다만, 주기함수를 이용했을 때 긴 sequence에 대해 성능이 더 좋을 수 있다.
4. Why Self-Attention
1. 각 layer마다 계산 복잡도가 줄어든다.
2. Recurrence를 없앰으로써 병렬 처리 가능
3. 장거리 지속성(Long-range dependency)에 대해 효율적 처리
※ 장거리 지속성 : 시간 간격이 증가하거나 점 사이의 공간 거리가 증가함에 따라 두 점의 통계적 의존성 붕괴
4. 해석 가능한 모델 형태로 만듦 : Self-attention의 확률값 출력
7. Conclusion
Transformer 모델
- Attention mechanism만 전적으로 사용
- Recurrent layer를 모두 제외
- 보다 높은 병렬성, 성능 개선
- 기계 번역 task : 다른 architecture보다 더 높은 성능
- 기계 번역 외에도 적용 가능성 높음
'심화 스터디 > NLP 스터디1' 카테고리의 다른 글
| [NLP 스터디] Improving Language Understanding by Generative Pre-Training 논문 리뷰 (0) | 2021.11.11 |
|---|---|
| [NLP 스터디] Improving Language Understanding by Generative Pre-Training 논문 리뷰 (0) | 2021.09.30 |
| NLP 스터디 1 소개 (0) | 2021.08.27 |



댓글 영역