
고정 헤더 영역
상세 컨텐츠
본문

1. Introduction
이제까지의 머신러닝의 일반적인 접근법은 어떠한 task에서 바라는 행동(예를 들면 질문과 질문에 대한 대답, 글과 글에 대한 요약 같은 것들)을 담은 데이터를 학습시켜서 이를 따라할 수 있는 시스템을 만들고, 다른 iid 데이터에서도 이 performance가 잘 작동되는지 test하는 것이었다. 그러나 이러한 접근법은 다루기가 힘들고 데이터 분포의 작은 변화에도 큰 영향을 받는다는 단점이 있었다.
시스템의 보편성에서 문제가 일어나는 이유를 특정 단일한 task에 training data를 제한했기 때문이라고 분석하였다. 그래서 더 넓은 영역의 domain과 task에 대한 performance를 측정하고 training을 할 수 있도록 구조를 고치는 것이 필요하다고 제안되었다.
이러한 multitask learning은 general performance를 향상시키는 프레임워크를 필요로 한다. 이를 위해서는 generalize에 적합한 수많은 예시가 필요하다. 이는 데이터를 적절한 규모만큼 만들고 시스템을 설계하는 것을 매우 어렵게 만든다. 그래서 multitask learning을 위해서는 추가적인 설정이 필요하다는 것이 제시되었다.
현재 가장 좋은 성능을 보이는 NLP는 pre-trained된 모델과 supervised fine-tuning을 결합한 것이다. 예를 들어 word vectors는 특정 task에 알맞은 구조로 학습된 후, recurrent 네트워크의 contextual representation로 transfer된다. 그러면 이 recurrent 구조는 더이상 task-specific하지 않고 self-attention block으로 transfer된 형태가 된다. 그러나 이 방식도 여전히 task-specific한 performance를 위해서 supervised training이 필요하다. 이를 피하기 위해서 다른 네트워크를 고안해야 한다.
그래서 이 논문에서는 두개의 작업을 연결하여 더 일반적인 방식의 transfer를 만들고자 한다. 언어 모델은 zero-shot setting까지 down-stream될 수 있다고 여긴다. 그리고 이 접근법이 zero-shot setting에서 다양한 작업을 할 수 있는 성능을 향상시킬 것으로 여긴다. zero-shot setting이란 모델을 만들 때 데이터만 주어지고 따로 특정한 학습을 시키지 않는 것을 말한다. 그래서 특정 task에 적용하기 위해서 새롭게 업데이트할 수 있다.
2. Approach
접근법의 핵심은 심볼들$(s_1,s_2,...,s_n)$으로 이루어진 텍스트 데이터$(x_1, x_2, ... ,x_n)$에 대한 unsupervised distribution estimation이다. 텍스트에는 순서가 있으므로 텍스트의 분포는 심볼들의 조건부확률로 표현된다.
$$p(x)=\Pi_{i=1}^{n}p(s_n|s_1,...,s_{n-1})$$
이 접근법은 샘플링을 쉽게 하고, $p(x)$에 대한 추정을 조건부 형태로 할 수 있도록 한다.
단일 task에 대한 학습은 $p(output|input)$이라는 조건부 분포를 추정하는 것과 같다. 그러나 general 시스템의 경우, $input$뿐만 아니라 task도 조건으로 정해져야 하므로 $p(output|input,task)$라는 조건부 분포를 추정하는 framework가 필요하다. 그래서 입력 데이터는 (task, input, output) 심볼들로 이루어진 포맷이다. 예를 들어, translation training일 때는 $\mathsf{(translate\ to\ french,\ english\ text,\ french\ text)}$ 포맷이다.
모델은 또한 어떤 output이 예측되어야 한다는 supervision없이 학습해야 한다. supervised objective와 unsupervised objective의 global minimum은 동일하므로 분포 추정을 training objective로 하는 toy setting을 정했다. 그러나 이전 실험들에서 충분히 많은 언어 모델은 이러한 toy setting에서도 다양한 task를 수행하였지만 supervised 방식에 비해 학습이 훨씬 느렸다.
그럼에도 불구하고 이는 굉장히 큰 발전이었다. 이제 자연스러운 언어를 더욱 직관적으로 학습하기 위해 dialog를 학습에 사용하고자 했는데 인터넷에는 상호작용 없는 텍스트도 많아서 제한적일 것이라는 우려가 있었다. 우리의 추측은 언어 모델이 충분한 능력을 갖고 있다면 procurement없이도 자연스러운 텍스트를 task에 알맞는 형태로 예측할 수 있다는 것이었다. 만약 모델이 이게 가능하다면 unsupervised multitask 학습을 수행할 수 있다. 이것이 zero-shot setting에서도 가능한지 확인해보았다.
2-1. Training Dataset
이 접근법은 자연스러운 텍스트를 위해서 많은 양의 다양한 데이터를 필요로 한다. 처음에는 Common Crawl에서 스크랩한 텍스트 데이터를 사용했으나 현재 모델이 감당가능한 양보다 훨씬 많은 텍스트가 있었고 퀄리티 이슈가 있어서 해석에 어려움이 있다는 단점이 있었다. 그래서 Common Crawl의 데이터 중 task에 알맞는 target 데이터만 추출해서 사용하고자 했으나 이렇게 task를 미리 정해두는 방식은 지양해야 했다.
그래서 퀄리티에 집중하는 새로운 웹을 찾아서 스크랩하고자 했다. 이를 위해 인간이 직접 고른 적이 있는 웹만 사용하기로 하였다. 그 시작으로 인터넷 커뮤니티 Reddit에서 사람들이 많이 스크랩한 웹 링크를 모았다. 이를 통해 수집한 텍스트 데이터는 총 4500만개의 링크를 수반한다. 여기서 2017년 12월 이후 데이터, 중복 데이터, 위키피디아 문서 제거 등의 작업을 거친 후 데이터 세트를 만들었다.
2-2. Input Representation
일반적으로 텍스트에는 소문자화, 토큰화 등의 작업이 필요하다. 유니코드 텍스트를 UTF-8 텍스트로 만드는 것은 이러한 작업을 충족한다.
Byte Pair Encoding(BPE)는 원 텍스트와 단어 사이의 중간 단계이다. BPE를 유니코드에 적용하면 전체 유니코드 텍스트를 요구하기 때문에 BPE에 적용할 수 있는 크기보다 훨씬 많아진다. 반대로 byte-level에 적용하는 BPE는 단어 기반의 텍스트만 요구하기 때문에 훨씬 작은 크기(256)으로 BPE를 적용하는 것이 가능하다. 이때 byte-level BPE는 변형이 일어난 단어도 같은 단어로 병합해버리는 단점이 있어서 이를 금지하는 조치를 따로 취했다.
이러한 input representation은 byte-level 접근법을 가능하게 하였으며, 전처리 된 어떤 데이터도 언어 모델에 적용할 수 있도록 하였다.
2-3. Model
모델은 GPT처럼 Transformer 기반이다. layer normalization은 각 블록의 입력 부분에 위치하여 pre-activation의 형태를 가진다. self attention 블록의 마지막에도 layer normalization을 추가하였다. residual layer의 초기 가중치는 $1/ \sqrt{N}$으로 하였다. 이때 N은 residual layer의 개수이다. context size는 512개에서 1024개의 토큰으로 늘렸고, 배치사이즈는 512를 사용하였다.
3. Experiment

위 표는 학습하거나 벤치마킹한 모델의 목록이다. 가장 작은 크기의 모델은 원래 GPT, 두번째로 작은 모델은 BERT, 가장 큰 모델은 GPT-2이다. 각 모델의 learning rate는 가장 좋은 perplexity값의 5% 내외에서 직접 튜닝하였다. 아직 모든 모델은 과소적합된 상태이다.
3-1. Language Modeling

일단 웹텍스트 언어 모델이 zero-shot domain에서 어떻게 작동하는지 이해해야 한다. 모델은 byte-level에서 작동하고 전처리나 토큰화를 필요로 하지 않으므로 이를 어떤 모델에서도 평가할 수 있다. 같은 양도 언어 모델에서 계산된 log probability를 canonical unit(character, byte, word)의 개수로 나눈 것으로 평가한다. 이때문에 분포에서 많이 벗어나며, 표준화된 텍스트나 토큰, 심지어 너무 드문 텍스트까지 참여하는 방식으로 언어 모델은 평가된다. 위 표에 나타난 결과는 de-토큰화를 사용하여 그러한 토큰과 전처리된 것들을 최대한 제거한 결과이다. de-토큰화는 invertible하기 떄문에 여전히 log probability를 사용할 수 있다. de-토큰화를 사용하여 GPT-2에 대해 2.5~5의 perplexity를 관측하였다.
웹텍스트 언어 모델은 최근 7-8개의 데이터을 사용하는 zero-shot setting에서도 좋은 성능을 보였다. 가장 많은 성능 향상을 보인것은 Penn Treebank나 WikiText-2처럼 적은 수의 토큰이 있는 경우였다. 그리고 long-term dependency를 관측하기 위한 LAMBADA와 Children's Book Test에서도 높은 성능 향상이 관측되었다. One Billion Word Benchmark에서는 전보다 더 나쁜 성능을 보였는데 너무 큰 데이터를 destructive한 모델에 넣으면서 큰 범위의 구조가 제거되었기 때문으로 예측하였다.
3-2. Children's Book Test
Children's Book Test(이하 CBT)는 서로 다른 종류의 단어에 대해서 언어 모델의 성능을 평가하는 것이다. CBT는 평가 지표로 perplexity보다는 accuracy를 사용한다. 여기서 accuracy는 제거된 단어에 대해 가능한 10개의 답 중 예측한 것이 틀렸는지, 맞았는지를 체크한다. 가능한 각각의 답에 대한 확률과 나머지 문장 요소를 기반으로 한 이 가능한 답의 확률을 조건부로 계산한다. 그리고 가장 높은 확률을 가진 것을 예측한다.

위 그림에서 볼 수 있듯이 모델 사이즈가 커질수록, 인간의 수행과 차이가 없어질수록 더 안정적인 모델이다. GPT-2는 보통 명사에 대해서는 93.3%, named entities에 대해서는 89.1%의 결과를 보였다. 또한 PTB 스타일의 토큰을 제거하기 위해 de-토큰화를 적용하였다.
3-3. LAMBADA
LAMBADA 데이터는 텍스트의 long-range dependency을 모델링하는 시스템의 성능을 평가한다. 문장의 마지막 단어를 예측하기 위해서 인간은 적어도 50개의 토큰을 필요로 한다. GPT-2는 최근 모델의 성능을 높였다. GPT-2의 에러는 마지막 단어에 맞지 않는 단어도 예측된다는 것을 보여주었는데 이는 언어 모델이 꼭 마지막 단어여야 한다는 추가적인 제약 조건을 사용하지 않았다는 것을 의미한다. stop-word filter를 추가하는 것은 모델의 성능을 4% 가량 높였다. 최근 모델에서 사용된 단어로 제한하는 제약 조건은 GPT-2에서는 오히려 나쁜 영향을 끼치는 것으로 보였다.
3-4. Winograd Schema Challenge
Winograd Schema Challenge는 상식적인 추론을 수행하는 시스템의 성능을 평가한다. 최근에 높은 확률로 텍스트의 모호성을 예측하면서 언어 모델로 이 challenge를 수행하는 것에서 큰 성능 향상이 있었다.

full scoring과 partial scoring을 둘 다 수행하여 위 그림에 성능을 나타내었다. GPT-2는 7% 가량의 accuracy 상승을 이끌어냈다.
3-5. Reading Comprehension
Conversation Question Answering dataset(이하 CoQA)는 7개의 다른 영역에 대한 질문자와 답변자의 대화로 이루어져 있다. CoQA는 모델의 독해 능력과 대화에 기반한 질문 대답 능력을 평가한다.
문서에 대한 GPT-2의 greedy decoding은 마지막 토큰이 development set에서 55 F1 수치를 달성했다. 이는 127,000개 이상의 질문-대답 쌍을 사용하지 않아도 기존 시스템의 성능의 3/4 이상을 달성할 수 있음을 보여준다.
3-6. Summarization
CNN과 Daily Mail dataset을 사용하여 summarization 성능을 확인한다. summarization을 수행하기 위해서 반복을 줄이고 더 추상적인 요약을 하는 Top-k random sampling으로 100개의 토큰을 뽑아낸다. 그리고 100개의 토큰에서 3개의 문장을 만들어서 summary로 사용한다.
3-7. Translation
translation task를 위해 언어 모델을 $\mathsf{english\ sentence\ =\ french\ sentence}$ 포맷으로 한정하였다. 그리고 $\mathsf{english\ sentence =}$의 최종 prompt에서는 greedy decoding 모델로 부터 추출하고, 첫번째로 만들어진 문장을 translation으로 사용한다. WMT-14 English-French 데이터셋에서 GPT-2는 5BLEU를 얻었는데 이는 이전 unsupervised 방식 모델인 word-by-word 모델보다 조금 안 좋은 결과였다. WMT-14 French-English에서는 11.5 BLEU를 얻으며 더 좋은 성능을 보였지만 여전히 가장 좋은 unsupervised translation 모델보다는 더 좋지 않았다. 그 이유는 웹텍스트를 수집하는 과정에서 영어가 아닌 텍스트들은 거의 제거를 했기 때문이다. 프랑스어 텍스트는 겨우 10MB 정도뿐이며, 이는 이전 unsupervised translation 모델이 학습에서 사용한 프랑스어 텍스트의 거의 500배 작은 양이다.
3-8. Question Answering
translation처럼 question answering task에서도 question-answer쌍의 포맷으로 언어 모델을 한정하였다. SQUAD처럼 독해 데이터셋을 사용했을 때, GPT-2는 4.1%의 질문에 올바르게 대답하였다. 모델의 capacity를 주요 factor로 내세워 5배 더 많은 질문에 올바르게 대답하게 되었으나, 여전히 기존 question answering 모델보다 훨씬 안 좋은 성능을 보였다.
4. Generalization vs Memorization
데이터셋의 크기가 늘어날수록 웹텍스트에 비슷한 논지를 가진 텍스트가 늘어나면서 중복 문제가 발생했다. 그래서 얼마나 많은 test data가 train data에도 나타나는지 확인하는 것은 중요하다.
이 작업을 위해서 웹텍스트 training 토큰의 8-gram을 포함한 Bloom 필터를 만들었다. 일단 소문자이면서 delimiter는 단일 공백으로만하여 텍스트를 표준화하였다. Bloom 필터는 false-positive 비율이 최대 $1\over{10^8}$인 것들만 추출하고, 비율이 0인 1M개의 텍스트를 확인하였다.

이 Bloom 필터는 train에 사용되는 웹텍스트 데이터와 test에 사용되는 데이터셋에서 동시에 발견되는 8-grams의 비율이 얼마나 있는지 계산해준다. 위 표에서 확인해보면 test 데이터셋은 평균 1-6%의 비율을 보여주는 반면, 웹텍스트는 평균 3.2%의 비율을 보여준다. 그래서 웹텍스트를 사용해도 된다는 결론이 나왔다.
Winograd Schema Challenge에서는 10개의 스키마타만 겹쳤고, CoQA에서는 15%의 문서가 겹쳤으며, LAMBADA에서는 평균 1.2%의 겹침 비율이 있었다. 전체적으로 이러한 웹텍스트 training 데이터와 specific evaluation 데이터의 겹침은 결과에 대해 작지만 일관된 이익을 주었다. 하지만 대부분의 데이터셋에서는 충분히 큰 겹침을 확인할 수 없었다.
비슷한 텍스트가 모델의 성능에 얼마나 영향을 주는지 확인하는 것은 중요하다. 더 나은 중복 제거 기술은 이를 도와주는데 현재는 n-gram overlap 방법이 추천되고 있다.
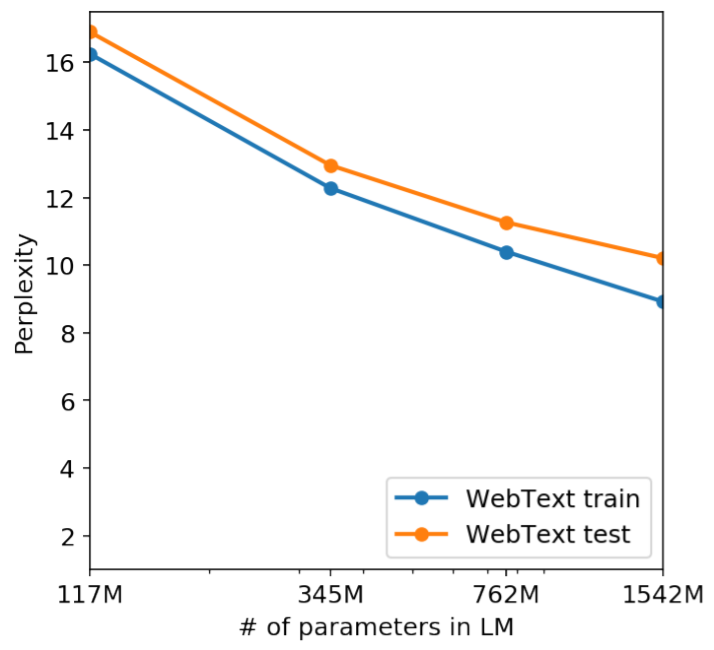
위 그림을 보면 웹텍스트를 train으로 사용할 때의 성능과 test로 사용할 때는 비슷하며, 모델 사이즈가 증가할수록 함께 상승한다. 이는 GPT-2가 여전히 웹텍스트에 대해서 과소적합 되어 있으며, 즉 memorize한 게 아님을 보여준다.
'심화 스터디 > NLP 스터디1' 카테고리의 다른 글
| [NLP 스터디] Improving Language Understanding by Generative Pre-Training 논문 리뷰 (0) | 2021.09.30 |
|---|---|
| [NLP 스터디] Attention Is All You Need 논문 리뷰 (0) | 2021.09.30 |
| NLP 스터디 1 소개 (0) | 2021.08.27 |



댓글 영역