
고정 헤더 영역
상세 컨텐츠
본문
작성자 : 14기 임혜리
참고 커널 : https://www.kaggle.com/munmun2004/nyc-taxi
NYC Taxi 한글커널
Explore and run machine learning code with Kaggle Notebooks | Using data from New York City Taxi Trip Duration
www.kaggle.com
0. Competition Introduction
- 이 대회의 목적은 뉴욕에서의 택시 여행 기간(단위 : 초)를 예측하는 모델을 만드는 것이었다.
- 일반적인 대회와는 다르게 가장 성과 측정치가 좋았던 사람을 뽑는 것보다는 통찰력이 있고 현실에서 사용 가능한 모델을 만드는 사람에게 보상을 지불하는 형태로 진행되었다.
- 성과 측정치 >RMSLE(Root mean squared logarithmic error)

- RMSLE는 예측값과 실제값이 모두 상당히 클 때 유용하다. 절대값이 아닌 상대적인 크기를 바탕으로 오류에 패널티를 적용하고, 음수 값이 있는 대상 열에는 허용되지 않는다.

- 데이터 크기가 커서 연습해보기 좋고 kaggle 대회에서 성적이 좋아 유명한 데이터 셋으로 알려져있다. 크게 어려우지 않으니 사용된 메서드들을 잘 기억해두면 좋을 것 같다!!
1. 데이터 불러오기 및 확인
2. EDA & FE
3. 모델링
4. 예측
1. 데이터 불러오기 및 확인
#필요한 라이브러리 설치
import numpy as np
import pandas as pd
import datetime as dt
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from scipy import stats
from scipy.stats import norm먼저 필요한 라이브러리를 설치해준다
#데이터 불러오기
train = pd.read_csv('/content/drive/MyDrive/nyc-taxi-trip-duration/train.zip (Unzipped Files)/train.csv')
test = pd.read_csv('/content/drive/MyDrive/nyc-taxi-trip-duration/test.zip (Unzipped Files)/test.csv')
sample_submission = pd.read_csv('/content/drive/MyDrive/nyc-taxi-trip-duration/sample_submission.zip (Unzipped Files)/sample_submission.csv')제공되는 데이터는 압축된 형태이므로 압축을 풀어준 후 불러오도록 한다
train.head(3)test.head(3)head 메서드로 train data와 test data의 상단부분을 확인한다.
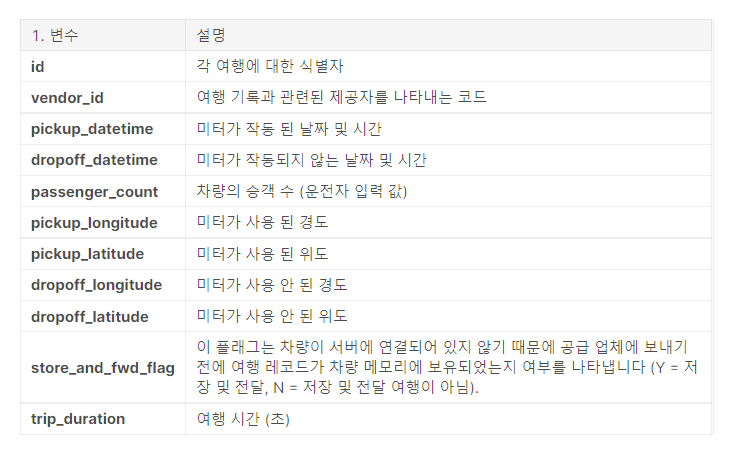
변수설명
train.shapetest.shapeshape 함수를 통해 데이터의 배열 형태를 확인한다.
train.info()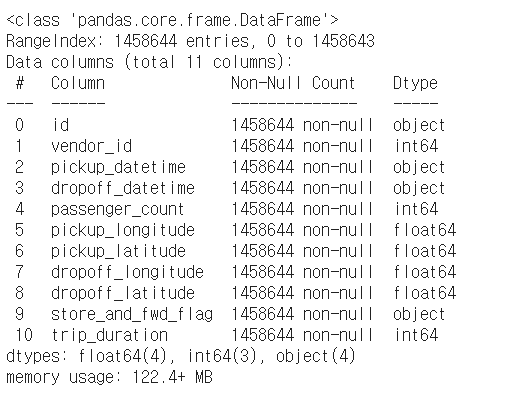
info 함수를 통해 데이터에 대한 전반적인 정보를 확인한다
df를 구성하는 행과 열의 크기, 컬럼명, 컬럼을 구성하는 값의 자료형 등을 알 수 있다.
#결측치 확인하기
train.isnull().sum()test.isnull().sum()결측치를 확인해보니 train data와 test data 모두 결측치가 없음을 확인할 수 있다.
2. EDA & FE
2.1 타겟변수 확인
#산점도
plt.scatter(range(train.shape[0]), np.sort(train['trip_duration']))
산점도를 그려 타겟변수를 확인한다.
train.shape[0]은 행의 개수를 나타내고 train.shape[1]은 열의 개수를 나타낸다.
위의 셀은 모든 행, 즉 모든 데이터에 대하여 trip_duration 값을 오름차순으로 정렬하고 산점도의 형태로 나타내는 코드이다.
산점도 확인 결과 이상치가 존재하는 것으로 보이니 이를 제거하도록 한다.
#타겟변수 유의수준 1%에 해당하는 데이터 범위를 지정하여 재설정
train[train.trip_duration < train.trip_duration.quantile(0.99)]타겟변수 유의수준 1%에 해당하는 데이터 범위를 지정하여 데이터를 재설정해준다.
sns.distplot(train.trip_duration.values, fit = norm)
이번에는 distplot을 통해 정규성을 확인해본다. 결과적으로 정규성을 띄지 않으니 log처리를 해준다.
sns.distplot(np.log1p(train.trip_duration.values), fit = norm)
자연로그 함수의 경우 x=0인 경우 y 값이 -무한대 값을 가지게 되어 에러가 발생하게 된다
이를 해결하기위해 x값에 1을 더해줘서 루트를 씌운 np.log10를 사용한다.
로그변환 후 정규성을 띄는 것을 볼 수 있으니 trip_duration 피처에 대해 로그 변환을 한다.
train['trip_duration'] = np.log(train['trip_duration'].values)
2.2 데이터 합치기
feature_names = list(test)
df_train = train[feature_names]
df = pd.concat((df_train, test))데이터 전처리를 편리하게 하기 위해 train data와 test data를 합친다
print(train.shape, test.shape, df.shape)df.head(3)합쳐서 생성된 df를 확인한다.
2.3 날짜변수
df['pickup_datetime'] = pd.to_datetime(df['pickup_datetime'])위에서 pickup_datetime의 자료형이 object임을 확인했다
이를 datetime 자료형으로 변환하기 위해 pd.to_datetime을 사용한다.
df['month'] = df['pickup_datetime'].dt.month
df['day'] = df['pickup_datetime'].dt.day
df['weekday'] = df['pickup_datetime'].dt.weekday
df['hour'] = df['pickup_datetime'].dt.hour
df['dayofweek'] = df['pickup_datetime'].dt.dayofweekdatatime자료형인 month, day, weekday, hour, dayofweek 열을 생성한다.
df.drop(['pickup_datetime'], axis = 1, inplace = True)그후 원래 있었던 pickup_datatime 열은 삭제한다.
df데이터를 확인해보면 위의 과정이 잘 실행된 것을 확인할 수 있다.
sns.countplot(df['hour'])
countplot을 통해 hour별 count를 확인해보니, 픽업이 새벽에는 매우 낮고 오후 6시에서 8시 사이에 제일 높은 것을 확인할 수 있다.
sns.countplot(df['dayofweek'])
dayofweek의 0은 월요일, 6은 일요일을 의미한다
픽업이 월요일에 가장 낮은 것을 확인할 수 있다.
2.4 거리변수
df['dist_long'] = df['pickup_longitude'] - df['dropoff_longitude']
df['dist_lat'] = df['pickup_latitude'] - df['dropoff_latitude']df['dist'] = np.sqrt(np.square(df['dist_long']) + np.square(df['dist_lat']))미터기가 시작되고 끝난 각각의 경도, 위도만큼 빼준 다음 이를 제곱해서 더하고 루트처리하여 새로운 파생변수를 만든 것이다.
하버사인 공식(Haversine Formula)

하지만 위도와 경도는 지구 모형 즉 구(sphere)를 기준으로 한 위치를 나타낸다는 점을 고려하여
하버사인 공식을 사용하여 두 지점 사이의 최단 거리를 구하는 것이 더 좋은 결과를 가져온다.
def ft_haversine_distance(lat1, lng1, lat2, lng2):
lat1, lng1, lat2, lng2 = map(np.radians, (lat1, lng1, lat2, lng2))
AVG_EARTH_RADIUS = 6371 #km
lat = lat2 - lat1
lng = lng2 - lng1
d = np.sin(lat * 0.5) ** 2 + np.cos(lat1) * np.cos(lat2) * np.sin(lng * 0.5) ** 2
h = 2 * AVG_EARTH_RADIUS * np.arcsin(np.sqrt(d))
return h
df['distance'] = ft_haversine_distance(df['pickup_latitude'].values,
df['pickup_longitude'].values,
df['dropoff_latitude'].values,
df['dropoff_longitude'].values)하버사인 공식을 사용해서 distance라는 변수를 추가해준다
df.boxplot(column = 'distance')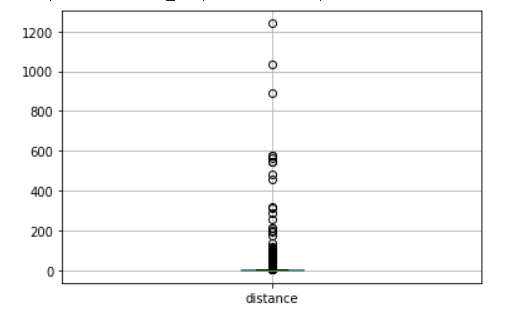
distance변수의 boxplot을 확인해보니 이상치가 존재한다는 것을 확인할 수 있다
df = df[(df.distance < 200)]이상치를 제거해준다
g_vendor = train.groupby('vendor_id')['trip_duration'].mean()
sns.barplot(g_vendor.index, g_vendor.values)공급 업체 별로 groupby를 한 상태에서 타겟 변수의 평균값을 확인해본 결과 별 차이가 없는 것을 확인할 수 있다
sfflag = train.groupby('store_and_fwd_flag')['trip_duration'].mean()
sns.barplot(sfflag.index, sfflag.values)store_and_fwd_flag 변수 또한 인덱스에 상관 없이 여행시간을 잘 구별하는 것을 확인할 수 있다
pc = train.groupby('passenger_count')['trip_duration'].mean()
sns.barplot(pc.index, pc.values)
2.5 범주형변수 one-hot encoding
df = pd.concat([df, pd.get_dummies(df['store_and_fwd_flag'],prefix = 'store')], axis=1)
df.drop(['store_and_fwd_flag'], axis=1, inplace=True)
df = pd.concat([df, pd.get_dummies(df['vendor_id'],prefix = 'vendor')], axis=1)
df.drop(['vendor_id'], axis=1, inplace=True)pandas의 get_dummies 함수를 통해 범주형 변수를 one-hot encoding해준다
get_dummies의 대표적인 파라미터 중 하나인 prefix는 생성할 dummy variable의 column 이름 앞에 붙을 이름을 지정하는 역할을 한다
df.head(3)데이터셋을 확인해보면 더미변수가 생성되고 그 전 범주형 변수의 열은 삭제되었음을 확인할 수 있다
2.6 상관관계
cor = df.corr()
mask = np.array(cor)
mask[np.tril_indices_from(mask)] = False
fig, ax = plt.subplots()
fig.set_size_inches(20,10)
sns.heatmap(cor, mask = mask, square = True, annot = True)변수들간의 상관관계를 파악한다
3. 모델링
#모델링 과정에 필요한 라이브러리 설치
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import mean_squared_log_error
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.linear_model import LinearRegression
3.1 train_test_split
df.drop(['id'], axis = 1, inplace = True)id 열은 모델에 추가할 변수에 해당하지 않으니 제거한 후 train_test_split를 진행한다
new_train = df[:train.shape[0]]
new_test = df[train.shape[0]:]df데이터 전처리를 끝마쳤기 때문에 다시 데이터를 나누어준다
target = train['trip_duration']target변수를 지정해준 후에
X_train, X_val, y_train, y_val = train_test_split(new_train, target, test_size = 0.2, shuffle = True)train_test_split를 진행한다
3.2 RMSLE
def rmsle_score(preds, true):
rmsle_score = (np.sum((np.log1p(preds)-np.log1p(true))**2)/len(true))**0.5
return rmsle_score이 대회의 평가 지표는 RMSLE 값이었다. 직접 함수를 지정해주거나 sklearn에서 제공하는 rmsle 지표를 사용할 수 있다
위의 셀은 직접 rmsle_score 함수를 만드는 것에 해당한다
from sklearn.metrics.scorer import make_scorer
RMSLE = make_scorer(rmsle_score)이는 sklearn에서 제공하는 rmsle지표를 사용한 것이다
3.3 통계확인
먼저 선형 회귀를 통해 통계를 확인해본다
import statsmodels.api as sm
model = sm.OLS(target.values, new_train.astype(float))re = model.fit()
re.summary()
모델의 설명력과 각 피처의 p-value 그리고 다중공선성의 문제를 확인해볼 수 있다
3.4 LightGBM
앙상블의 부스팅 기법인 lightgbm과 xgboost를 사용할 것인데, 우선 부스팅이 무엇인지 먼저 살펴보자
BOOSTING이란?
여러개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에는 가중치를 부여하면서 학습과 예측을 진행하는 것을 말한다
예측 성능이 뛰어나서 앙상블 학습을 주도하고 있다
LightGBM이란?
Gradient Boosting 프레임워크로 Tree 기반 학습 알고리즘이다.
말 그대로 'light' 가볍다 > 속도가 빠르다
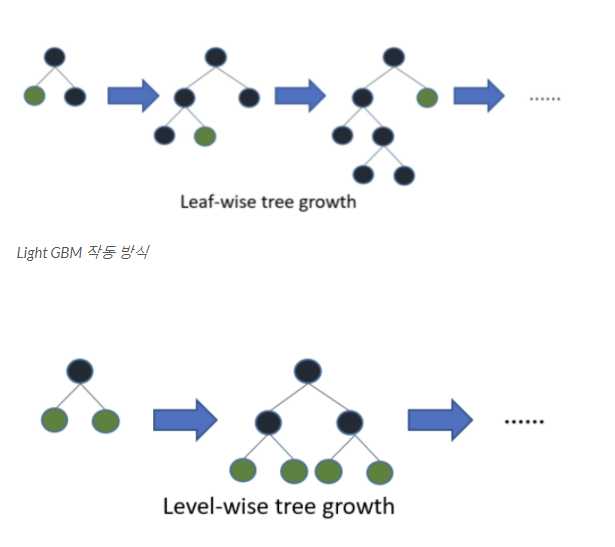
기존의 다른 tree 기반 알고리즘과 어떻게 다를까?
Light GBM은 Tree가 수직적으로 확장되는 반면에 다른 알고리즘은 Tree가 수평적으로 확장된다.
즉 Light GBM은 leaf-wise 인 반면 다른 알고리즘은 level-wise 이다.
이는 확장하기 위해서 max delta loss를 가진 leaf를 선택하게 되는 것이라고 말할 수 있다.
동일한 leaf를 확장할 때, leaf-wise 알고리즘은 level-wise 알고리즘보다 더 많은 loss, 손실을 줄일 수 있다.
XGBOOST보다 학습에 걸리는 시간이 훨씬 적고 메모리 사용량도 상대적으로 적다.
또한 LIGHTGBM은 더 최신의 것이기에 기능상의 다양성이 더 많다.
lightgbm 모델에 대해 더 자세히 공부하고 싶다면 아래 url을 참고하면 좋을 것 같다
[참고] https://nurilee.com/2020/04/03/lightgbm-definition-parameter-tuning/
LightGBM 이란? 그리고 Parameter 튜닝하기
LightGBM에 관한 좋은 medium 포스트가 있어서 한글로 번역한 내용을 공유드려봅니다 :) Pushkar Mandot의 원문 바로가기: 안녕하세요, 머신러닝은 이 세상에서 가장 빠르게 성장하는 분야입니다. 매일
nurilee.com
import lightgbm as lgbm
#파라미터 세팅
lgb_params = {
'metric' : 'rmse',
'learning_rate': 0.1,
'max_depth': 25,
'num_leaves': 1000,
'objective': 'regression',
'feature_fraction': 0.9,
'bagging_fraction': 0.5,
'max_bin': 1000 }#lgbm 데이터셋으로 변환
lgb_df = lgbm.Dataset(new_train,target)
#훈련
lgb_model = lgbm.train(lgb_params, lgb_df, num_boost_round=1500)
#예측
pred = lgb_model.predict(new_test)
pred_lgb = np.exp(pred)
3.5 XGBoost
XGBoost란?
XGBoost는 GBM에 기반하고 있지만, 표준의 GBM의 단점인 느린 수행시간 및 과적합 규제 부재 등의 문제를 해결해서 매우 각광받고 있다.
1) 일반적으로 분류와 회귀영역에서 뛰어난 예측성능을 발휘한다.
2) 일반적인 GBM은 순차적으로 Weak learner가 가중치를 증감하는 방법으로 학습하기 때문에, 전반적으로 속도가 느리지만 XGBoost는 병렬 수행 및 다양한 기능으로 표준 GBM에 비해 빠른 수행성능을 보장합니다.
xgboost 모델에 대해 더 자세히 공부하고 싶다면 아래 url을 참고하면 좋을 것 같다
[참고] https://zereight.tistory.com/254
Ensemble(앙상블) 학습이란? (필사) feat. 랜덤포레스트,XGBoost, LightGBM
(파이썬 머신러닝 완벽가이드 발췌) - 개요 앙상블 학습을 통한 분류는 여러개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종예측을 도출하는 기법을 말합니다. 어려운 문제의
zereight.tistory.com
import xgboost as xgb
#파라미터 세팅
params = {
'booster': 'gbtree',
'objective': 'reg:linear',
'learning_rate': 0.1,
'max_depth': 14,
'subsample': 0.8,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'silent': 1}#xgb.DMatrix 생성
dtrain = xgb.DMatrix(new_train, target)
#훈련
gbm = xgb.train(params,
dtrain,
num_boost_round = 200)
#예측
pred_test = np.exp(gbm.predict(xgb.DMatrix(new_test)))DMatrix는 넘파이 입력 파라미터를 받아서 만들어지는 XGBoost만의 전용 데이터 세트를 말한다.
파이썬래퍼 XGBoost와 사이킷런래퍼 XGBoost의 가장 큰 차이는 파이썬래퍼는 학습용과 테스트 데이터 세트를 위해 별도의 DMatrix를 생성한다는 것이다.
4. 예측
#ensemble = (0.8*pred_lgb + 0.2*pred_test) 0.42295
#ensemble = (0.7*pred_lgb + 0.3*pred_test) 0.38148
ensemble = (0.6*pred_lgb + 0.4*pred_test) #0.38124
#ensemble = (0.55*pred_lgb + 0.45*pred_test) 0.38126앙상블을 통해서 lgb와 xgb를 6:4 비율로 했을 때 가장 작은 결과값이 나왔음을 확인할 수 있다
sub = pd.DataFrame()
sub['id'] = test.id
sub['trip_duration'] = ensemble
sub.head(3)sub.to_csv('submission.csv', index=False)sub이라는 데이터프레임에 id와 trip_duration 변수를 생성하여 각각 test.id, ensemble 값을 대입해주고 이를 csv 파일로 변환하여 제출하면 끝이다!!



댓글 영역