
고정 헤더 영역
상세 컨텐츠
본문 제목
[코드 분석 스터디] Multi-class classification : Image classification - TensorFlow Speech Recognition Challenge
본문
참고 커널 URL
https://www.kaggle.com/harunshimanto/speech-classification-using-cnn
Speech Classification using CNN
Explore and run machine learning code with Kaggle Notebooks | Using data from TensorFlow Speech Recognition Challenge
www.kaggle.com
https://www.kaggle.com/aggarwalrahul/nlp-speech-recognition-model-dev
NLP - Speech Recognition Model Dev
Explore and run machine learning code with Kaggle Notebooks | Using data from TensorFlow Speech Recognition Challenge
www.kaggle.com
데이터의 특징
- 총 65,000개의 1초 내외의 음성파일
- "Yes", "No", "Up", "Down", "Left", "Right", "On", "Off", "Stop", "Go", "Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine", "Bed", "Bird", "Cat", "Dog", "Happy", "House", "Marvin", "Sheila", "Tree", "Wow", "_background_noise_"의 31개 폴더 존재
- "Yes", "No", "Up", "Down", "Left", "Right", "On", "Off", "Stop", "Go", "Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", and "Nine"의 20개가 core words
- "_background_noise_"를 제외한 나머지 10개가 auxiliary words
- core words 중 "Yes", "No", "Up", "Down", "Left", "Right", "On", "Off", "Stop", "Go"가 Test에서 예측을 위해 쓰임
<Multi-class Classification>
1. Data Exploration and Visualization
2. Resampling
3. Preprocessing
4. Split into train and validation set
5. Model building
6. Diagnostic plot
1. Data Exploration and Visualization
train_audio_path = '...input/tensorflow-speech-recognition-challenge/train/audio/'
filename = 'yes/0a7c2a8d_nohash_0.wav'
sample_rate, samples = wavfile.read(str(train_audio_path) + filename)
fig = plt.figure(figsize=(14, 8))
ax1 = fig.add_subplot(211)
ax1.set_title('Raw wave of ' + '/tensorflow-speech-recognition-challenge/train/audio/yes/0a7c2a8d_nohash_0.wav')
ax1.set_xlabel('time')
ax1.set_ylabel('Amplitude')
ax1.plot(np.linspace(0, sample_rate/len(samples), sample_rate), samples)
print(sample_rate)
print(len(samples))
wavfile.read()를 실행할 경우 sample_rate과 sample을 출력한다.
sample_rate: 음성 파일의 주파수(초당 샘플 수, 스칼라)
sample: 그 수치(위상, 벡터)
ipd.Audio(samples, rate=sample_rate)
print(sample_rate)
np.array(samples, dtype='float64')audio signal의 sampling rate을 확인.
16000개의 sample_rate이 array 형태로 표현된다.
2. Resampling
samples=np.array(samples, dtype='float64')
samples = librosa.resample(samples, sample_rate, 8000)
ipd.Audio(samples, rate=8000)librosa 라이브러리를 통해 하나의 audio signal을 resample한다.
이 경우 기존의 16000Hz를 8000Hz로 downsampling한 것이다.
(대부분의 speech와 관련된 frequency가 8000Hz이기 때문에 8000Hz로 resampling하는 것이다)
labels=os.listdir(train_audio_path)
#find count of each label and plot bar graph
no_of_recordings=[]
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
no_of_recordings.append(len(waves))
#plot
plt.figure(figsize=(30,5))
index = np.arange(len(labels))
plt.bar(index, no_of_recordings)
plt.xlabel('Commands', fontsize=12)
plt.ylabel('No of recordings', fontsize=12)
plt.xticks(index, labels, fontsize=15, rotation=60)
plt.title('No. of recordings for each command')
plt.show()
labels=["yes", "no", "up", "down", "left", "right", "on", "off", "stop", "go"]
duration_of_recordings=[]
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path + '/' + label + '/' + wav)
duration_of_recordings.append(float(len(samples)/sample_rate))
plt.hist(np.array(duration_of_recordings))
음성파일의 길이를 파악해보았을 때 거의 대부분의 파일이 1초 정도의 길이인 것을 알 수 있다. 1초보다 짧은 길이의 음성파일도 일부 존재한다.
3. Preprocessing
all_wave = []
all_label = []
for label in labels:
print(label)
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
for wav in waves:
samples, sample_rate = librosa.load(train_audio_path + '/' + label + '/' + wav, sr = 16000)
samples = librosa.resample(samples, sample_rate, 8000)
if(len(samples)== 8000) :
all_wave.append(samples)
all_label.append(label)전체 train data를 16000Hz에서 8000Hz로 resampling을 진행한다.
resampling한 것들 중에서 길이가 1초가 되지 않는 데이터를 제거한다.
(samples의 길이가 8000이 아닌 데이터를 제외시킨다.)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y=le.fit_transform(all_label)
classes= list(le.classes_)10개의 label에 대해 정수로 encoding해준다.
from keras.utils import np_utils
y=np_utils.to_categorical(y, num_classes=len(labels))keras.utils패키지의 to_categorical함수를 통해 labels를 one-hot-encoding시켜준다.
all_wave = np.array(all_wave).reshape(-1,8000,1)
all_wave.shapeConv1D의 input이 3D가 되어야 하기 때문에 기존의 2Darray를 3D로 reshape 시켜준다.
그 결과 all_wave.shape이 (21312, 8000, 1)가 나온다.
4. Split into train and validation set
from sklearn.model_selection import train_test_split
x_tr, x_val, y_tr, y_val = train_test_split(np.array(all_wave),np.array(y),stratify=y,test_size = 0.2,random_state=777,shuffle=True)train_test_split을 통해 train set과 validation set을 8:2의 비율로 나눈다.
5. Model building
from keras.layers import Dense, Dropout, Flatten, Conv1D, Input, MaxPooling1D
from keras.models import Model
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras import backend as K
K.clear_session()
inputs = Input(shape=(8000,1))
#First Conv1D layer
conv = Conv1D(8,13, padding='valid', activation='relu', strides=1)(inputs)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.2)(conv)
#Second Conv1D layer
conv = Conv1D(16, 11, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.2)(conv)
#Third Conv1D layer
conv = Conv1D(32, 9, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.2)(conv)
#Fourth Conv1D layer
conv = Conv1D(64, 7, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.2)(conv)
#Flatten layer
conv = Flatten()(conv)
#Dense Layer 1
conv = Dense(256, activation='relu')(conv)
conv = Dropout(0.2)(conv)
#Dense Layer 2
conv = Dense(128, activation='relu')(conv)
conv = Dropout(0.2)(conv)
outputs = Dense(len(labels), activation='softmax')(conv)
model = Model(inputs, outputs)
model.summary()
* Conv1D와 Conv2D, Conv3D의 차이
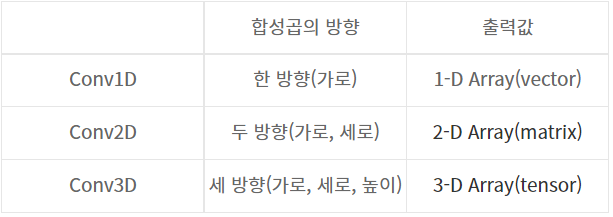
- Conv1D(filters,kernel_size,strides=1,padding='valid',activation=None, strides=1)
이미지 데이터 때 쓰는 Conv2D와 같아 보이지만 필터의 형태가 다르다.
Conv1D는 kernel_size를 1개의 정수로 표현, Conv2D는 (int, int)로 표현된다.
Conv1D는 필터의 입력값의 차원 수와 높이가 동일하게 연산되기 때문에 가로길이만 설정해주면 된다.
padding='valid'는 no padding을 의미한다. size가 줄어든다.
- Pooling: feature map의 크기를 줄이거나 주요한 특징을 뽑아내기 위해서 합성곱 신경망 이후에 적용되는 기법
MaxPooling1D(pool_size=2,strides=None,padding='valid',data_format=None)이 기본
pool_size : 풀링을 적용할 필터의 크기(pool_size 클수록 output크기 작아짐)
- Dropout
신경망 모델의 overfitting 문제를 해결해주는 방법. 전체 입력값 중 rate의 크기만큼을 0으로 만든다.
Dropout(rate)
- Dense
Dense(unit,activation=None)
unit: output의 크기
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10, min_delta=0.00001)
mc = ModelCheckpoint('best_model.hdf5', monitor='val_acc', verbose=1, save_best_only=True, mode='max')EarlyStopping을 통해 overfitting 되는 것을 방지한다.
- EarlyStopping의 인자
monitor: EarlyStopping의 기준이 되는 값. (val_loss의 경우 val_loss가 더 이상 감소하지 않을 때 멈춤)
min_delta: 개선된 것으로 간주하기 위한 최소한의 변화량.
mode='min': val_loss는 작을수록 좋기 때문에 min을 사용.
- ModelCheckpoint의 인자
save_best_only: True인 경우 monitor의 기준으로 가장 좋은 값만 저장.
False일 경우 매 epoch마다 filepath{epoch}으로 저장.
history=model.fit(x_tr, y_tr ,epochs=100, callbacks=[es,mc], batch_size=8, validation_data=(x_val,y_val))history=model.fit(x_tr, y_tr ,epochs=100, callbacks=[es,mc], batch_size=8, validation_data=(x_val,y_val))
#원래 kernal에서의 batch_size는 32였지만 GPU용량 부족으로 batch_size를 8까지 줄여서 진행했습니다.
Epoch 1/100
2132/2132 [==============================] - 27s 10ms/step - loss: 2.2856 - accuracy: 0.1239 - val_loss: 2.2628 - val_accuracy: 0.1536
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 2/100
2132/2132 [==============================] - 19s 9ms/step - loss: 2.2122 - accuracy: 0.1652 - val_loss: 2.1631 - val_accuracy: 0.1696
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 3/100
2132/2132 [==============================] - 19s 9ms/step - loss: 2.0900 - accuracy: 0.2064 - val_loss: 1.9819 - val_accuracy: 0.2454
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 4/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.9357 - accuracy: 0.2665 - val_loss: 1.8310 - val_accuracy: 0.3059
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 5/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.6872 - accuracy: 0.3618 - val_loss: 1.4618 - val_accuracy: 0.4830
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 6/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.4967 - accuracy: 0.4383 - val_loss: 1.3098 - val_accuracy: 0.5238
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 7/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.3585 - accuracy: 0.5070 - val_loss: 1.2723 - val_accuracy: 0.5665
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 8/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.2641 - accuracy: 0.5417 - val_loss: 1.3859 - val_accuracy: 0.5161
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 9/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.1836 - accuracy: 0.5691 - val_loss: 1.1988 - val_accuracy: 0.5721
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 10/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.1125 - accuracy: 0.6030 - val_loss: 1.3179 - val_accuracy: 0.5470
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 11/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.0545 - accuracy: 0.6185 - val_loss: 1.0231 - val_accuracy: 0.6493
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 12/100
2132/2132 [==============================] - 19s 9ms/step - loss: 1.0065 - accuracy: 0.6395 - val_loss: 1.0583 - val_accuracy: 0.6338
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 13/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.9422 - accuracy: 0.6596 - val_loss: 0.9055 - val_accuracy: 0.6746
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 14/100
2132/2132 [==============================] - 20s 9ms/step - loss: 0.8816 - accuracy: 0.6861 - val_loss: 0.9060 - val_accuracy: 0.6775
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 15/100
2132/2132 [==============================] - 20s 9ms/step - loss: 0.8375 - accuracy: 0.7025 - val_loss: 0.8050 - val_accuracy: 0.7255
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 16/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.7902 - accuracy: 0.7206 - val_loss: 0.7216 - val_accuracy: 0.7462
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 17/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.7461 - accuracy: 0.7328 - val_loss: 0.8496 - val_accuracy: 0.6981
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 18/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.7120 - accuracy: 0.7487 - val_loss: 0.7322 - val_accuracy: 0.7460
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 19/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.6676 - accuracy: 0.7620 - val_loss: 0.8069 - val_accuracy: 0.7267
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 20/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.6587 - accuracy: 0.7668 - val_loss: 0.6807 - val_accuracy: 0.7645
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 21/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.6087 - accuracy: 0.7860 - val_loss: 1.7722 - val_accuracy: 0.4931
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 22/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.5988 - accuracy: 0.7868 - val_loss: 0.6996 - val_accuracy: 0.7553
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 23/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.5768 - accuracy: 0.7944 - val_loss: 0.6533 - val_accuracy: 0.7685
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 24/100
2132/2132 [==============================] - 20s 9ms/step - loss: 0.5548 - accuracy: 0.8041 - val_loss: 0.8555 - val_accuracy: 0.7028
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 25/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.5383 - accuracy: 0.8090 - val_loss: 0.6302 - val_accuracy: 0.7870
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 26/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.5147 - accuracy: 0.8172 - val_loss: 0.6289 - val_accuracy: 0.7947
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 27/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.5072 - accuracy: 0.8175 - val_loss: 0.6476 - val_accuracy: 0.7795
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 28/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4937 - accuracy: 0.8245 - val_loss: 0.5872 - val_accuracy: 0.7985
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 29/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4834 - accuracy: 0.8279 - val_loss: 0.5898 - val_accuracy: 0.8011
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 30/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4642 - accuracy: 0.8354 - val_loss: 0.9839 - val_accuracy: 0.6958
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 31/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4649 - accuracy: 0.8362 - val_loss: 0.6650 - val_accuracy: 0.7978
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 32/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4367 - accuracy: 0.8440 - val_loss: 0.5738 - val_accuracy: 0.8142
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 33/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4408 - accuracy: 0.8447 - val_loss: 0.6837 - val_accuracy: 0.7858
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 34/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4256 - accuracy: 0.8500 - val_loss: 0.5823 - val_accuracy: 0.8076
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 35/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4086 - accuracy: 0.8555 - val_loss: 0.6772 - val_accuracy: 0.7755
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 36/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4086 - accuracy: 0.8558 - val_loss: 0.5862 - val_accuracy: 0.8086
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 37/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.4054 - accuracy: 0.8573 - val_loss: 0.6184 - val_accuracy: 0.7898
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 38/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.3840 - accuracy: 0.8656 - val_loss: 0.6303 - val_accuracy: 0.7938
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 39/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.3844 - accuracy: 0.8674 - val_loss: 0.6476 - val_accuracy: 0.7898
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 40/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.3704 - accuracy: 0.8682 - val_loss: 0.8218 - val_accuracy: 0.7319
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 41/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.3759 - accuracy: 0.8691 - val_loss: 0.6074 - val_accuracy: 0.8095
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 42/100
2132/2132 [==============================] - 19s 9ms/step - loss: 0.3635 - accuracy: 0.8718 - val_loss: 0.5874 - val_accuracy: 0.8109
WARNING:tensorflow:Can save best model only with val_acc available, skipping.
Epoch 00042: early stopping
6. Diagnostic plot
from matplotlib import pyplot
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
pyplot.show()
'심화 스터디 > 코드 분석 스터디' 카테고리의 다른 글
| [코드 분석 스터디] Regression - New York City Taxi Trip Duration (0) | 2021.09.27 |
|---|---|
| [코드 분석 스터디] Binary Classification: Image Classfication - Statoil/C-CORE Iceberg Classifier Challenge (2) | 2021.09.25 |
| [코드 분석 스터디] Porto Seguro's Safe Driver Prediction 캐글 커널 필사 (3) | 2021.09.16 |
| [코드 분석 스터디] Binary Classification - Titanic (EDA to Prediction) (5) | 2021.09.16 |
| [코드 분석 스터디] 스터디 진행 계획 및 방법 (0) | 2021.09.09 |



댓글 영역